A Practical Guide to BeautifulSoup Web Scraping
- Nov 15, 2025
- 12 min read
When people talk about BeautifulSoup web scraping, they're talking about using a fantastic Python library to make sense of the messy HTML and XML code that makes up a webpage. It excels at parsing static websites—pages where all the content is right there in the initial HTML source code. BeautifulSoup takes that jumble of code and turns it into something you can actually work with.
Setting Up Your First Web Scraper

Before you can start pulling data from the web, you need to get your tools in order. Think of this initial setup as laying the foundation for all your future scraping projects. We're going to build a clean environment and install a couple of essential libraries to get you from zero to your first successful scrape.
Installing the Core Libraries
Your journey into web scraping with Python really starts with two libraries: and . They work as a team. The library is your scout; it goes out and fetches the raw HTML content from a website. Once it brings that back, BeautifulSoup steps in as the master decoder, parsing the HTML into a structured object that’s a breeze to navigate.
Getting them installed is simple. Just fire up your terminal or command prompt and run these two commands using pip, Python's package manager:
pip install requestspip install beautifulsoup4
That's it. With these two libraries installed, you have everything you need to grab and parse a static webpage. This combo is incredibly popular for a reason—it's simple, efficient, and gets the job done without a lot of overhead.
In fact, BeautifulSoup is the go-to choice for many developers, holding a massive 43.5% market share as the dominant HTML parsing library. Its reputation is built on how well it handles static content with minimal resource usage, which is a huge advantage for smaller projects.
Comparing BeautifulSoup With Other Scraping Tools
Here's a quick look at how BeautifulSoup stacks up against other popular tools, helping you choose the right one for your project.
Tool | Primary Use Case | Handles JavaScript | Learning Curve |
|---|---|---|---|
BeautifulSoup | Parsing HTML/XML from static pages | No | Low |
Scrapy | Large-scale, asynchronous scraping projects | No (needs integration) | Medium |
Selenium | Automating browsers to scrape dynamic sites | Yes | High |
Playwright | Modern browser automation for dynamic sites | Yes | High |
While tools like Selenium or Playwright are necessary for JavaScript-heavy sites, BeautifulSoup remains the king of simplicity for straightforward HTML parsing.
Your First Successful Scrape
Alright, let's put this theory into practice. We'll write a quick script to grab the content from a simple webpage and pull out its title. Getting this first small win under your belt is a great way to build confidence.
Here’s the complete code to fetch a page and parse its title:
import requestsfrom bs4 import BeautifulSoup
The URL of the page we want to scrape
url = 'http://quotes.toscrape.com/'
Use requests to get the page content
response = requests.get(url)
Turn the raw HTML into a BeautifulSoup object
soup = BeautifulSoup(response.content, 'html.parser')
Find and print the page title
print(soup.title.string)
When you run this Python script, it will print "Quotes to Scrape" to your console. That's your confirmation—you've officially fetched and parsed your first webpage!
This fundamental loop of fetching, parsing, and extracting is the core of nearly every scraper you'll build. For a more detailed walkthrough, you can explore our complete guide on how to scrape a website with Python.
Finding and Extracting The Data You Need

Alright, so you've pulled the raw HTML from the page. You're now staring at the site's entire blueprint. This is where the real fun begins in your beautifulsoup web scraping journey—sifting through that mountain of code to pull out the exact nuggets of information you're after.
This is where BeautifulSoup really shines. It gives us powerful tools to navigate this code and turn it into clean, structured data. The two methods you'll lean on most are and . These are the absolute workhorses of data extraction.
Think of as your precision tool. It scans the parsed HTML and stops as soon as it finds the first element that matches what you're looking for. It’s perfect when you know you only need one thing, like the main title of an article.
On the flip side, is your bulk-gathering tool. It casts a wide net, collecting every single element that fits your criteria and handing them back to you in a neat list. This is what you'll use to grab all the product titles from a category page or every single link from a website's footer.
Targeting Elements with Precision
To make these methods work, you have to give them clear instructions. You can target elements by their tag, their class, their ID, and more.
Let's say we're trying to scrape a basic product listing with this HTML structure:
Here’s how you could pull out the different pieces of information:
By Tag Name: To get the product name, you can just tell BeautifulSoup to find the tag. Simple. *
By Class Name: Need the price? Target its CSS class. Just remember to use with an underscore, since is a reserved keyword in Python itself. *
By ID: To grab the entire product card container, its unique ID is the most direct route. *
Pro Tip: A common rookie mistake is assuming an element will always be there. If comes up empty, it returns . If your code then tries to call on , your whole script will crash. Always wrap your extraction logic in a simple check to handle cases where an element might be missing.
A More Intuitive Approach with CSS Selectors
While and are essential, I personally find myself using CSS selectors most of the time. If you have any experience with web development or just styling a webpage, the syntax will feel incredibly natural and, frankly, more powerful.
BeautifulSoup gives us two methods for this: and .
is the equivalent of , grabbing only the first match.
is the equivalent of , returning a list of all matches.
Let's revisit our product card example and see how much cleaner it can be with CSS selectors:
See how you can chain selectors together? It makes navigating complex, nested HTML far more straightforward. Mastering this skill is incredibly valuable. The global web scraping industry, which depends on tools just like this, is projected to swell to $3.5 billion by 2025 as more businesses hunt for data-driven insights. If you're curious, you can find more on web scraping trends and their economic impact in this detailed analysis.
Scraping Across Multiple Pages and Forms

Let’s be honest, data is rarely handed to you on a single, neat page. It's usually scattered across dozens of pages in a product catalog or tucked away behind a search form. To build a scraper that’s actually useful, you have to teach it how to move around a site just like a person would.
This is where things get interesting. We'll move beyond scraping just one URL and start building logic that can follow "Next" buttons, submit forms, and pull down a complete dataset, not just a small piece of it.
Navigating Through Paginated Content
Pagination is that familiar "Next," "Previous," or set of page numbers you see at the bottom of search results or blog archives. For our scraper, the goal is simple: find the link to the next page, grab the data, and keep going until there are no more pages to visit.
A loop is your best friend for this task. The logic is straightforward: as long as a "Next" link exists, keep scraping.
Here's the general flow I follow:
First, scrape the initial page you land on.
Then, hunt for the "Next" page link. I usually target it by its text content or a specific CSS class.
If you find it, build the full URL for the next page and loop back to the first step.
If that link is gone, you’ve hit the end of the line. Your loop naturally stops.
This simple loop is the key to methodically crawling through hundreds or even thousands of pages to assemble a complete dataset.
Pro Tip: Watch out for relative links! Often, the attribute for a "Next" button will be something like , not a full URL. You'll need to join this with the base domain to create a URL that can actually visit.
Interacting With HTML Forms
What about data that only shows up after you’ve typed something into a search box? BeautifulSoup can’t fill out a form on its own, but when paired with the library, it can easily handle the results. The trick is to mimic what your browser does when you click "Submit."
This typically means sending an HTTP POST request instead of the usual GET. Along with that request, you'll need to include a payload—basically, a dictionary containing the form's data.
Here's how to tackle it:
Inspect the form in your browser. Right-click the form and use your developer tools to find the element. You're looking for two things: the attribute (the URL the data is sent to) and the attribute of each field you want to fill.
Build the payload. Create a Python dictionary. The keys will be the attributes from the inputs, and the values will be the data you want to "type" into them.
Send the POST request. Use the function, passing in the form's URL and your payload dictionary.
The server will respond with a new HTML page containing the results. You can then feed that response directly into BeautifulSoup and parse it like any other webpage. This technique is a game-changer, giving you access to tons of data that isn't immediately visible.
Building a Scraper That Lasts
Anyone can cobble together a script that works once on a perfect day. But what separates a hobbyist from a professional in beautifulsoup web scraping is building something that runs reliably and doesn't get you blocked. This is about more than just code; it's about anticipating failure and acting like a good web citizen.
Let's be real: scrapers break. A lot. The website might go down for maintenance, your Wi-Fi could hiccup, or—most commonly—a developer updates the site's layout, and your carefully crafted CSS selectors suddenly point to nothing. If you don't plan for this, your script will crash and burn.
The classic solution here is wrapping your core logic in blocks. This is your safety net. It catches exceptions, like a when the network fails or an when a BeautifulSoup method comes up empty. Instead of halting everything, your code can simply log the error and move on to the next page.
How to Scrape Without Being a Jerk
Beyond just keeping your script alive, you need to think about how it behaves. An aggressive, anonymous bot hammering a server is the fastest way to get your IP address permanently banned. Scraping ethically isn't just about good karma; it's a pragmatic approach to ensure your data sources remain available.
Here are three things I never, ever skip:
Identify Yourself with a User-Agent: The library basically announces "I am a script!" by default. Always change this. Set a custom User-Agent header to either identify your bot or, more commonly, mimic a standard web browser. It’s a simple, transparent first step.
Check the File: Nearly every website has a file at the root of its domain (like ) that lays out the rules for automated bots. Before you write a single line of scraping code, read this file and respect the rules. It's the website owner telling you where you're not welcome.
Slow Down: Don't bombard a server with back-to-back requests. It’s a dead giveaway you’re a bot and puts an unnecessary strain on their infrastructure. A simple between requests is often all you need to fly under the radar and mimic how a human browses.
Sticking to these principles is your first and best defense against getting blocked. It makes your scraping sustainable and ensures you aren't disrupting the very websites you need data from.
Making these practices a habit is essential. If you want to go even deeper, our guide on 10 web scraping best practices covers more advanced techniques for responsible scraping. When you pair solid error handling with ethical behavior, you’re no longer just writing a script—you’re building a professional, dependable tool that can run for the long haul.
Handling JavaScript-Rendered Content
Sooner or later, every web scraper runs into the same wall. You can see the data you want right there on the screen, clear as day, but when your script pulls down the HTML, it's just... gone. This is almost always the handiwork of JavaScript, which loads and displays content after your browser has already received the initial page.
Think of it this way: BeautifulSoup is a fantastic HTML parser, but it’s not a web browser. It can only see the raw HTML that the library hands it. It has absolutely no ability to run the JavaScript that modern sites rely on to fetch prices, update live scores, or populate search results.
Is JavaScript Really the Problem? Here’s How to Know for Sure
Before you start overhauling your entire scraping setup, it's worth taking a minute to confirm that client-side JavaScript is actually the issue. The quickest test is right in your browser.
Just navigate to the target page, pop open your developer tools, find the settings, and disable JavaScript.
Reload the page. If the information you need suddenly disappears, you've found your culprit. The content isn't in the initial HTML, which means a simple call will never see it. You'll need a different approach.
Bringing in the Heavy Hitters: Browser Automation
To scrape dynamic content, you have to let the website run its scripts and render the page completely, just like a real browser would. This is where tools like Selenium or Playwright come into play.
These libraries let you control an actual web browser (like Chrome or Firefox) from your Python script. Your code can instruct the browser to wait for the JavaScript to finish loading, and then you can grab the final, fully-rendered HTML. From there, you just pass that complete HTML source over to BeautifulSoup to parse.
It’s a powerful one-two punch:
Selenium or Playwright does the heavy lifting of browser control and JavaScript execution.
BeautifulSoup takes over to do what it does best: parsing the clean HTML with its familiar, easy-to-use syntax.
If you're new to this technique, our guide to Selenium web scraping with Python is a great place to start. It walks you through setting up this exact workflow.
The Turnkey Solution: A Web Scraping API
While controlling a browser yourself gets the job done, it's not without headaches. You're suddenly responsible for managing browser drivers, dealing with slow page loads, and you’re still an easy target for basic anti-bot systems. For a more professional and scalable solution, a dedicated web scraping API is often the right call.
Services like ScrapeUnblocker basically act as a super-powered proxy. Instead of making a simple call to the target site, you make a call to the API. It handles all the messy stuff behind the scenes.
This infographic lays out a quick decision tree for ethical scraping—a critical first step before diving into the technical challenges.
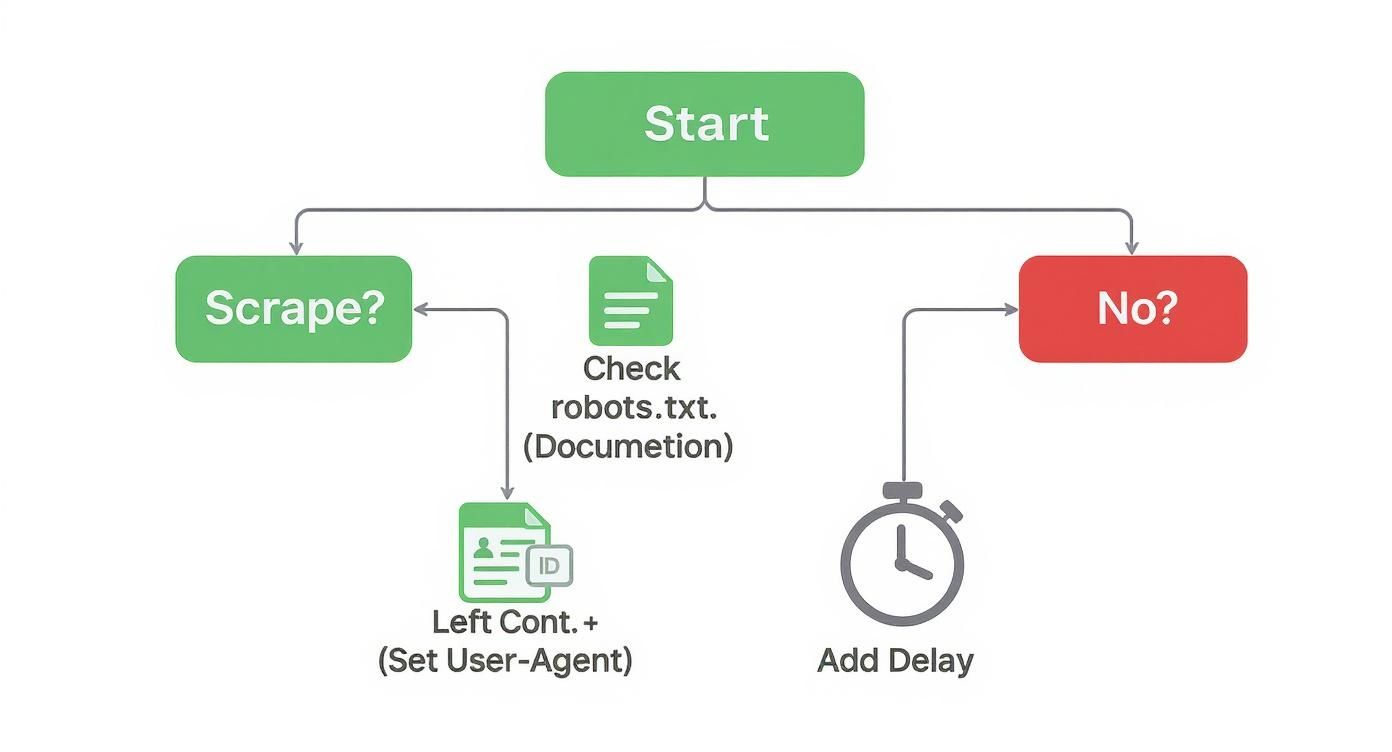
The chart emphasizes checking and managing request rates, which are precisely the kinds of details an API can handle for you automatically.
Using a scraping API means you can offload the hardest parts of the job: managing residential proxies to avoid IP bans, solving CAPTCHAs, and rendering JavaScript-heavy pages. Your task is simplified back to what you started with—just parsing the final HTML with BeautifulSoup. You get to focus entirely on extracting the data.
Got Questions About Scraping with BeautifulSoup?
Once you get your hands dirty with BeautifulSoup web scraping, you'll inevitably hit a few common roadblocks. Getting ahead of these can save you a ton of time banging your head against the wall. Let's walk through some of the questions I see pop up all the time.
Can BeautifulSoup Handle JavaScript-Heavy Websites?
The short answer? Nope, not on its own.
BeautifulSoup is a parser. Its one and only job is to understand the structure of the HTML or XML you feed it. It doesn't have a JavaScript engine, which means it’s completely blind to any content that gets loaded dynamically after the initial page loads. Think of it like reading the blueprint of a house—it can't tell you what furniture the owners will add later.
For modern, dynamic sites, you need a two-part strategy:
First, you need something that can act like a real browser. Tools like Selenium or Playwright are perfect for this. They'll load the page, run all the scripts, and wait for the dynamic content to pop into place.
Then, once the page is fully rendered, you grab the final HTML and hand it off to BeautifulSoup.
This combo gives you the best of both worlds: a powerful browser automation tool to deal with the JavaScript, and BeautifulSoup's wonderfully simple API to actually pull out the data you need.
HTML Parser vs. XML Parser: What's the Difference?
The real difference boils down to how strict they are. For pretty much 99% of your web scraping projects, you'll want to stick with an HTML parser. Python's built-in is a good start, and is a popular, faster alternative. These parsers are designed to be lenient because, let's be honest, a lot of HTML out there is a hot mess.
An XML parser, like , is the complete opposite. It's a stickler for the rules and demands perfectly structured, valid XML. A single missing closing tag or a tiny syntax error will cause it to throw a fit and stop dead in its tracks. Unless you know for a fact you're scraping a clean XML data feed, just stick with an HTML parser.
Pro Tip: Always start with or for web scraping. They're built for the wild, often-broken nature of the web in a way that rigid XML parsers simply aren't.
How Do I Keep From Getting Blocked?
This is the big one. Building a scraper that doesn't get shut down is all about making your script look less like a robot and more like a person browsing the web.
Start with the simple stuff. Always check the file on the site to see what they consider off-limits. Next, make sure you're setting a common header in your requests so you look like a standard browser, not a script. Most importantly, slow down! Add a pause between your requests with to avoid hammering their server.
For tougher targets, you'll need to step up your game by using a pool of rotating proxies to constantly change your IP address.
Juggling anti-bot systems, JavaScript rendering, and proxy rotation can feel like a full-time job. A service like ScrapeUnblocker takes care of all that complexity behind the scenes. It deals with the blocks and delivers the clean HTML, so all you have to do is focus on parsing the data with BeautifulSoup. You can try it for free and see how much simpler scraping can be.



Comments